Differentially Private
Gaussian Processes
Presented by Mike Smith, University of Sheffield
michaeltsmith.org.uk
m.t.smith@sheffield.ac.uk
@mikethomassmith
Differential Privacy, summary
We want to protect a user from a linkage attack...
...while still performing inference over the whole group.
Making a dataset private is more than just erasing names.
To achieve a level of privacy one needs to add randomness to the data.
This is a fundamental feature of differential privacy.
See The Algorithmic Foundations of Differential Privacy by Dwork and Roth for a rigorous introduction to the framework.Differential Privacy for Gaussian Processes
Differential Privacy for GPs
We have a dataset in which the inputs, $X$, are public. The outputs, $\mathbf{y}$, we want to keep private.
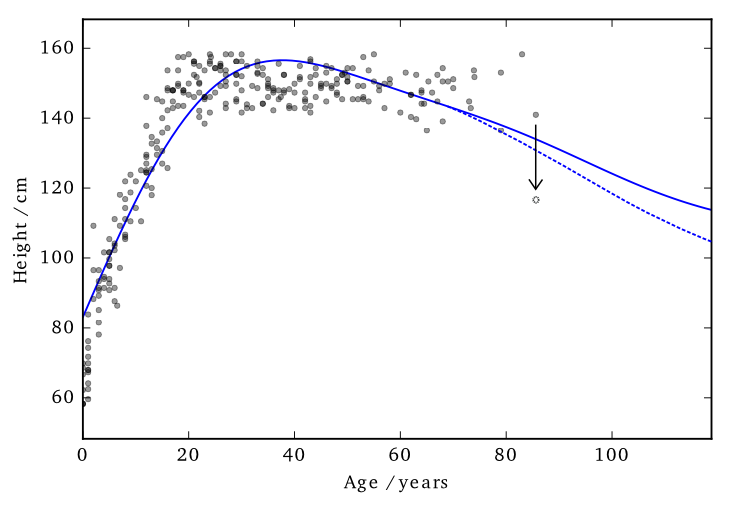
Data consists of the heights and weights of 287 women from a census of the !Kung
Vectors and Functions
Hall et al. (2013) showed that one can ensure that a version of $f$, function $\tilde{f}$ is $(\varepsilon, \delta)$-differentially private by adding a scaled sample from a GP prior.
3 pages of maths ahead!
Applied to Gaussian Processes
We applied this method to the GP posterior.
The covariance of the posterior only depends on the inputs, $X$. So we can compute this without applying DP.
The mean function, $f_D(\mathbf{x_*})$, does depend on $\mathbf{y}$. $f_D(\mathbf{x_*}) = \mathbf{k}_*^\top K^{-1} \mathbf{y}$
We are interested in finding $|| f_D(\mathbf{x_*}) - f_{D^\prime}(\mathbf{x_*}) ||_H^2$
...how much the mean function (in RKHS) can change due to a change in $\mathbf{y}$.
Applied to Gaussian Processes
Using the representer theorem, we can write $|| f_D(\mathbf{x_*}) - f_{D^\prime}(\mathbf{x_*}) ||_H^2$
as:
$\Big|\Big|\sum_{i=1}^n k(\mathbf{x_*},\mathbf{x}_i) \left(\alpha_i - \alpha^\prime_i\right)\Big|\Big|_H^2$
where $\mathbf{\alpha} - \mathbf{\alpha}^\prime = K^{-1} \left(\mathbf{y} - \mathbf{y}^\prime \right)$
$\Big|\Big|\sum_{i=1}^n k(\mathbf{x_*},\mathbf{x}_i) \left(\alpha_i - \alpha^\prime_i\right)\Big|\Big|_H^2$
where $\mathbf{\alpha} - \mathbf{\alpha}^\prime = K^{-1} \left(\mathbf{y} - \mathbf{y}^\prime \right)$
We constrain the kernel: $-1\leq k \leq 1$ and we only allow one element of $\mathbf{y}$ and $\mathbf{y}'$ to differ (by at most $d$).
So only one column of $K^{-1}$ will be involved in the change of mean (which we are summing over).
The distance above can then be shown to be no greater than $d\;||K^{-1}||_\infty$
Applied to Gaussian Processes
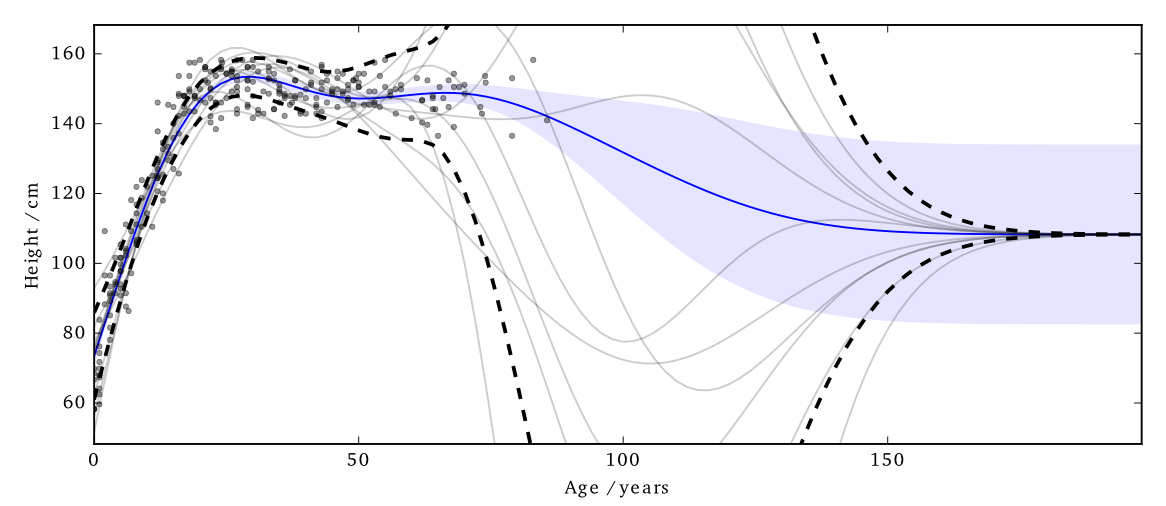
This 'works' in that it allows DP predictions...but to avoid too much noise, the value of $\varepsilon$ is too large (here it is 100)
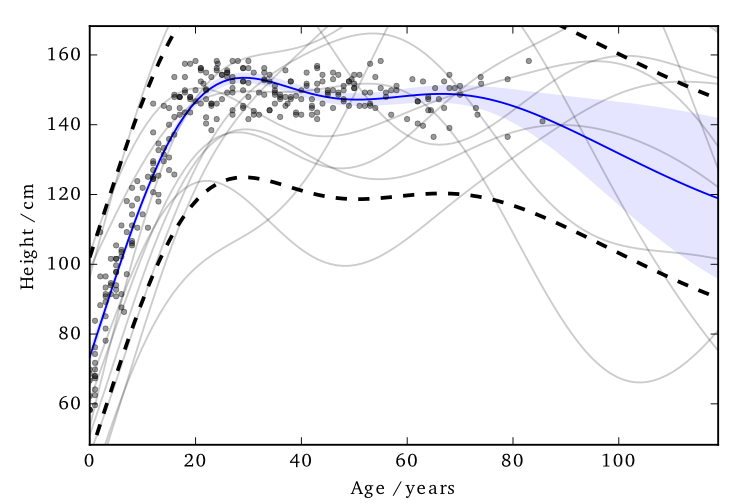
EQ kernel, $l = 25$ years, $\Delta=100$cm
Inducing Inputs
Using sparse methods (i.e. inducing inputs) can help reduce the sensitivity a little. We'll see more on this later.
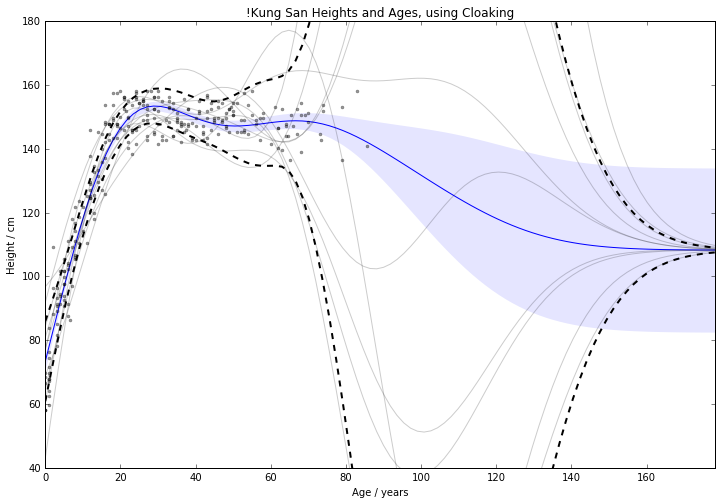
Cloaking
So far we've made the whole posterior mean function private...
...what if we just concentrate on making particular predictions private?
Effect of perturbation
Previously I mentioned that the noise is sampled from the GP's prior.
This is not necessarily the most 'efficient' covariance to use.

Effect of perturbation

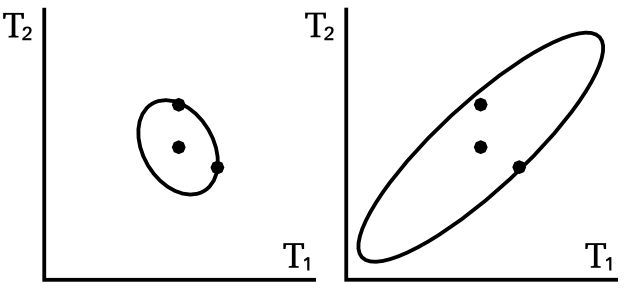
Cloaking
Left: Ideal covariance. Right: actual covariance
DP Vectors
Hall et al. (2013) also presented a bound on vectors.
Find a bound ($\Delta$) on the scale of the output change, in term of its Mahalanobis distance (wrt the added noise covariance).
$\sup_{D \sim {D'}} ||M^{-1/2} (\mathbf{y}_* - \mathbf{y}_{*}')||_2 \leq \Delta$
We use this to scale the noise we add:
$\frac{\text{c}(\delta)\Delta}{\varepsilon} \mathcal{N}_d(0,M)$
We get to pick $M$
Cloaking
Intuitively we want to construct $M$ so that it has greatest covariance in those directions most affected by changes in training points, so that it will be most able to mask those changes.
The change in posterior mean predictions is,
$\mathbf{y}_* - \mathbf{y}'_* = K_{*f} K^{-1} (\mathbf{y}-\mathbf{y}')$
The effect of perturbing each training point on each test point is represented in the cloaking matrix, $C = K_{*f} K^{-1}$
Cloaking
We assume we are protecting only one training input's change, by at most $d$.
So $\mathbf{y}-\mathbf{y}'$ will be all zeros except for one element, $i$.
So the change in test points will be (at most)
$\mathbf{y}_*' - \mathbf{y}_* = d C_{:i}$
We're able to write the earlier bound as,
$d^2 \sup_{i} \mathbf{c}_i^\top M^{-1} \mathbf{c}_i \leq \Delta$
where $\mathbf{c}_i \triangleq C_{:i}$
Cloaking
Dealing with $d$ elsewhere and setting $\Delta = 1$ (thus $0 \leq \mathbf{c}_i^\top M^{-1} \mathbf{c}_i \leq 1$) and minimise $\log |M|$ (minimises the partial entropy).
Using lagrange multipliers and gradient descent, we find
$M = \sum_i{\lambda_i \mathbf{c}_i \mathbf{c}_i^\top}$
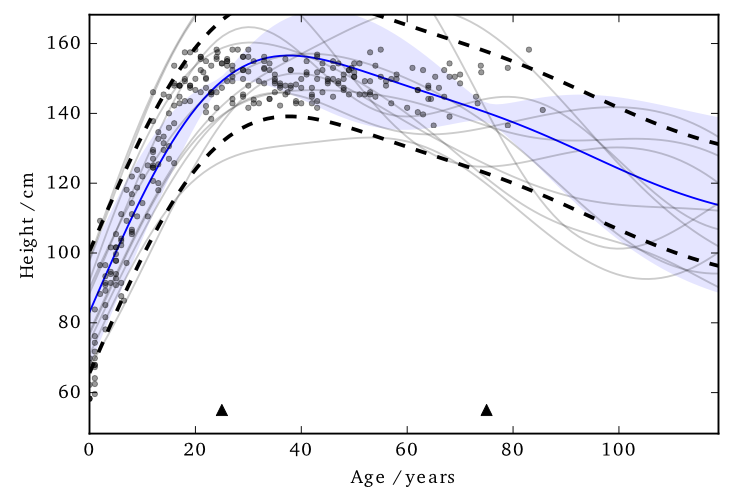
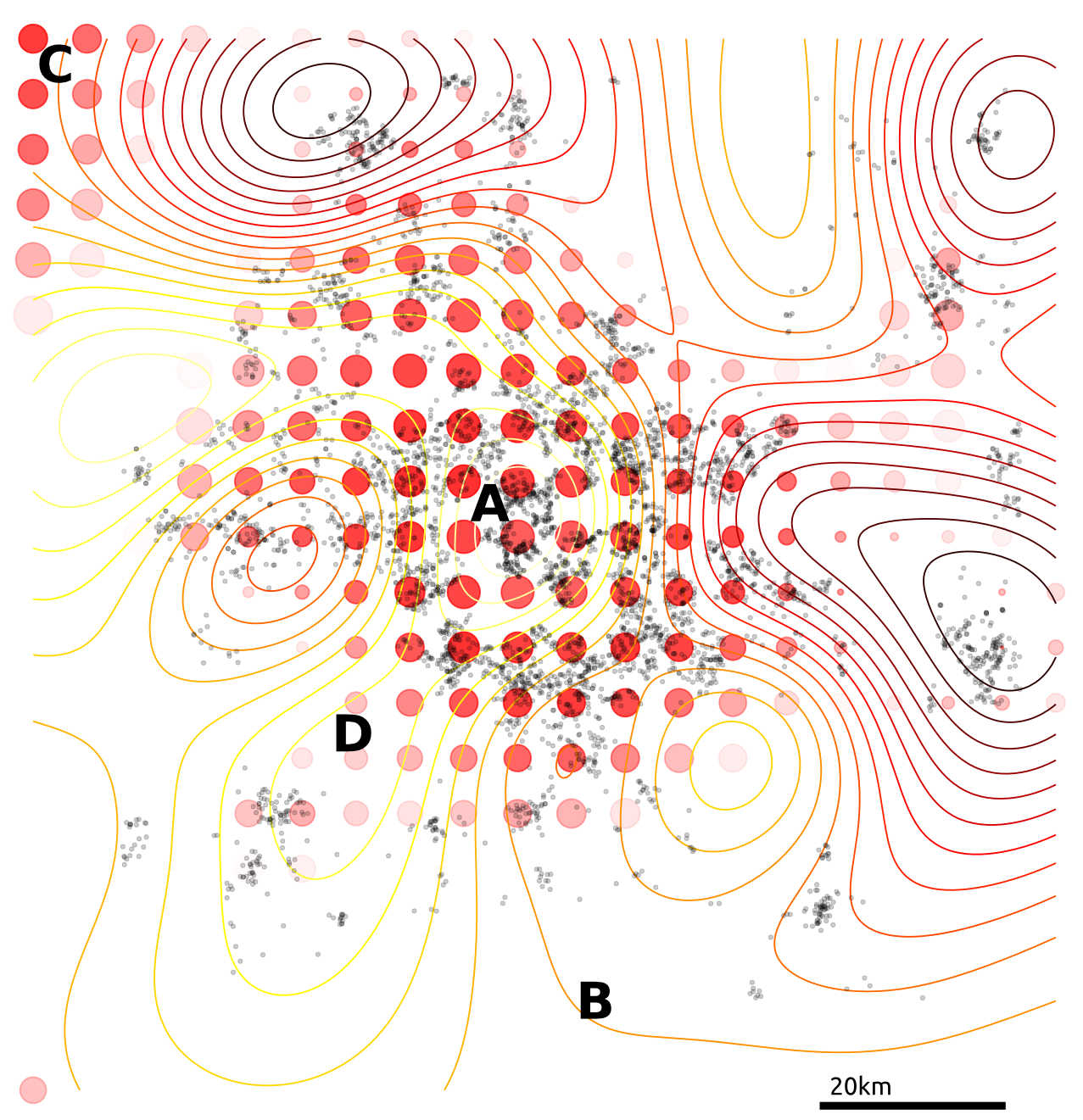
Cloaking: Results
The noise added by this method is now practical.
EQ kernel, $l = 25$ years, $\Delta=100$cm, $\varepsilon=1$
Cloaking: Results
It also has some interesting features;
- Less noise where data is concentrated
- Least noise far from any data
- Most noise just outside data
House prices around London
Citibike
Tested on 4d citibike dataset (predicting journey durations from start/finish station locations).
The method appears to achieve lower noise than binning alternatives (for reasonable $\varepsilon$).
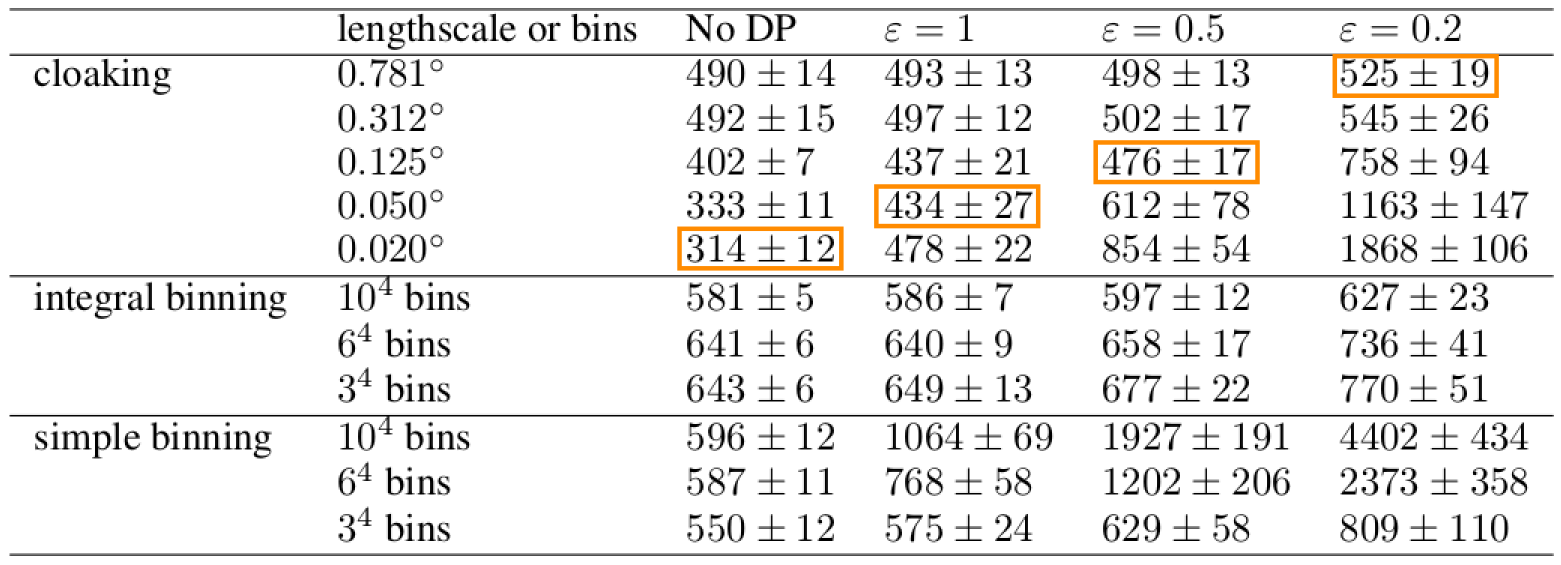 lengthscale in degrees, values above, journey duration (in seconds)
lengthscale in degrees, values above, journey duration (in seconds)
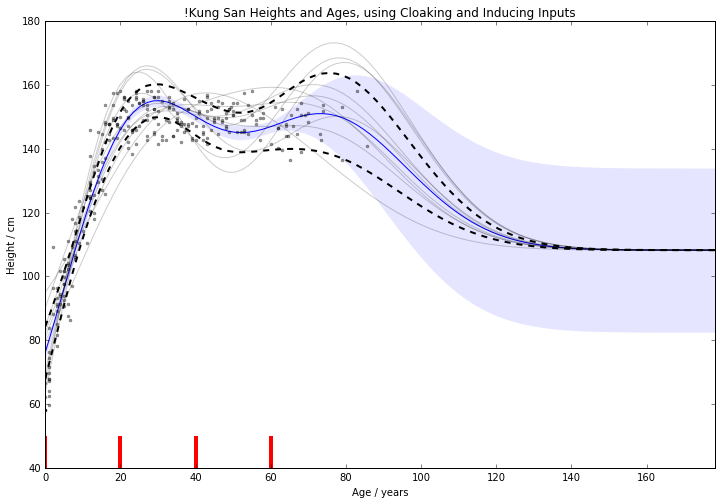
Cloaking and Inducing Inputs
Outliers poorly predicted.
Too much noise around data 'edges'.
Use inducing inputs to reduce the
sensitivity to these outliers.
Cloaking (no) Inducing Inputs
Cloaking and Inducing Inputs
Results
For 1d !Kung, RMSE improved
from $15.0 \pm 2.0 \text{cm}$ to $11.1 \pm 0.8 \text{cm}$
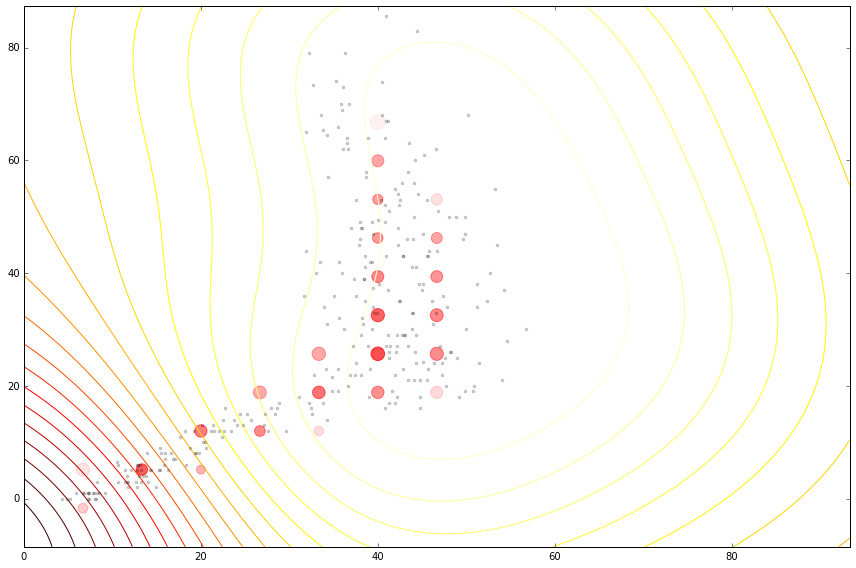
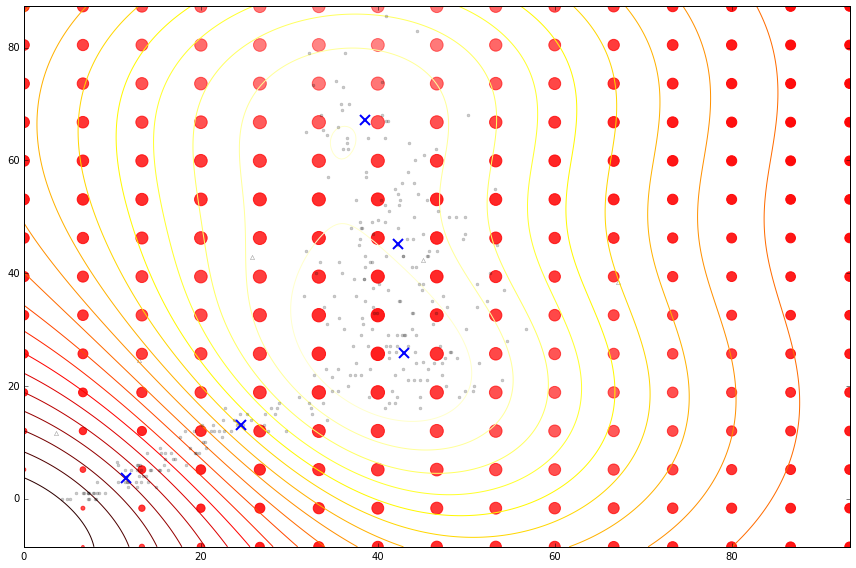
Use Age and Weight to predict Height
For 2d !Kung, RMSE improved
from $22.8 \pm 1.9 \text{cm}$ to $8.8 \pm 0.6 \text{cm}$
Note that the uncertainty across x-validation runs smaller.
2d version benefits from data's 1d manifold.
Cloaking (no) Inducing Inputs
Cloaking and Inducing Inputs
Summary We have developed an improved method for performing differentially private regression.
Future work Multiple outputs, GP classification, DP Optimising hyperparameters, Making the inputs private.
Thanks Funders: EPSRC; Colleagues: Mauricio, Neil, Max.
Recruiting Deep Probabilistic Models: 2 year postdoc (tinyurl.com/shefpostdoc)
The go-to book on differential privacy, by Dwork and Roth;
Dwork, Cynthia, and Aaron Roth. "The algorithmic foundations of differential privacy." Theoretical Computer Science 9.3-4 (2013): 211-407.
link
I found this paper allowed me to start applying DP to GP;
Hall, Rob, Alessandro Rinaldo, and Larry Wasserman. "Differential privacy for functions and functional data." The Journal of Machine Learning Research 14.1 (2013): 703-727.
link
Articles about the Massachusetts privacy debate
Barth-Jones, Daniel C. "The're-identification'of Governor William Weld's medical information: a critical re-examination of health data identification risks and privacy protections, then and now." Then and Now (June 4, 2012) (2012). link
Ohm, Paul. "Broken promises of privacy: Responding to the surprising failure of anonymization." UCLA Law Review 57 (2010): 1701. link
Narayanan, Arvind, and Edward W. Felten. "No silver bullet: De-identification still doesn’t work." White Paper (2014). link
Howell, N. Data from a partial census of the !kung san, dobe. 1967-1969. https://public.tableau. com/profile/john.marriott#!/vizhome/ kung-san/Attributes, 1967.
Images used: BostonGlobe: Mass Mutual, Weld. Harvard: Sweeney. Rich on flickr: Sheffield skyline.
{kind=link}
{kind=link}
{kind=link}